HBNU-MD News
- We collected a data set of campus face masks.
- Face masks are collected by various devices, car cameras, drones and mobile phones of various models.
- In addition to the photos collected on campus, some photos in RMFD are also combined, and the number of photos in the final data set is nearly 10000.
- If you want to add some real face mask photos to our dataset, you can send an email to 1090654389@qq.com.
What is HBNU-MD?
HBNU-MD is a data set of face masks, with photos from the campus and some from RMFD,Including:
- Nearly 6000 face objects
- Nearly 15000 face objects
- More than 6000 campus images
- Nearly 3000 images from RMFD
- Nearly 10000 images
Participants
Teacher
Students
Dataset Donwload
(2)hbnudq2 Extraction code:hbn3
(3)hbnudq3 Extraction code:hbn2
(4)Internet Extraction code:hbn4
(5)AIZOO Extraction code:hbn5
HBNU-MD example

Support
![]()
Photos of participants
Teacher
 CHEN Yongming CHEN Yongming |
|---|
Member of Intelligent Robot Laboratory
 YU Feiyang YU Feiyang |
 ZHAO Feiyu ZHAO Feiyu |
 WANG Xiaoxuan WANG Xiaoxuan |
 LIU Huan LIU Huan |
|---|
Member of collecting and labeling
 WU Shixuan WU Shixuan |
 XU Wei XU Wei |
 ZHU Ruidi ZHU Ruidi |
 LI Pengbo LI Pengbo |
 HU Jiahao HU Jiahao |
|---|---|---|---|---|
 WAMG Shun WAMG Shun |
 ZHENG Penghui ZHENG Penghui |
 LI Changliu LI Changliu |
 ZHANG Yedong ZHANG Yedong |
 TANG Chengqian TANG Chengqian |
 ZHAO Jiarui ZHAO Jiarui |
 CUI Yuexuan CUI Yuexuan |
 LUO Ri LUO Ri |
 YANG Yifan YANG Yifan |
Explore
Explore the dataset using our online interface. Get a sense of the scale and type of data in COCO.
Download
Download the dataset, including tools, images, and annotations. See cocoDemo in either the Matlab or Python code.
External
Download external datasets that complement or extend COCO, including COCO annotations for object attributes, VQA, human actions and interactions with objects, scene text, saliency, etc.
Tasks: Detection | DensePose | Keypoints | Stuff | Panoptic | Captions
Learn about the individual challenge tasks. Come to the workshops to learn about the state of the art. Once you're ready, compete in the challenges to earn prizes and opportunities to present your work!
Participate: Data Format | Results Format | Test Guidelines | Upload Results
Develop your algorithm. Run your algorithm on COCO and save the results using the format described. Then, learn about the guidelines for using the val and test sets and participating in challenges.
Evaluate: Detection | Keypoints | Stuff | Panoptic | Captions
Evaluate results of your system. See evalDemo in either the Matlab or Python code and evalCapDemo in the Python code for detection and caption demo code. Upload your results to the test-set eval servers to compete in public challenges!
Leaderboard: Detection | Keypoints | Stuff | Panoptic | Captions
Check out the state-of-the-art! See what algorithms are best at the various tasks.
COCO Explorer
COCO 2017 train/val browser (123,287 images, 886,284 instances). Crowd labels not shown.

















































































Tools
COCO API
Images
2014 Train images [83K/13GB]
2014 Val images [41K/6GB]
2014 Test images [41K/6GB]
2015 Test images [81K/12GB]
2017 Train images [118K/18GB]
2017 Val images [5K/1GB]
2017 Test images [41K/6GB]
2017 Unlabeled images [123K/19GB]
Annotations
2014 Train/Val annotations [241MB]
2014 Testing Image info [1MB]
2015 Testing Image info [2MB]
2017 Train/Val annotations [241MB]
2017 Stuff Train/Val annotations [1.1GB]
2017 Panoptic Train/Val annotations [821MB]
2017 Testing Image info [1MB]
2017 Unlabeled Image info [4MB]
1. Overview
Which dataset splits should you download? Each year's images are associated with different tasks. Specifically:
Detection 2018, Keypoints 2018, Stuff 2018, Panoptic 2018,
Detection 2019, Keypoints 2019, Stuff 2019, Panoptic 2019,
Detection 2020, Keypoints 2020, Panoptic 2020
If you are submitting to a 2017, 2018, 2019, or 2020 task, you only need to download the 2017 images. You can disregard earlier splits. Note: the split year refers to the year the image splits were released, not the year in which the annotations were released.
For efficiently downloading the images, we recommend using gsutil rsync to avoid the download of large zip files. Please follow the instructions in the COCO API Readme to setup the downloaded COCO data (the images and annotations should go in coco/images/ and coco/annotations/). By downloading this dataset, you agree to our Terms of Use.
Our data is hosted on Google Cloud Platform (GCP). gsutil provides tools for efficiently accessing this data. You do not need a GCP account to use gsutil. Instructions for downloading the data are as follows:
The splits are available for download via rsync are: train2014, val2014, test2014, test2015, train2017, val2017, test2017, unlabeled2017. Simply replace 'val2017' with the split you wish to download and repeat steps (2)-(3). Finally, you can also download all the annotation zip files via:
The download is multi-threaded, you can control other options of the download as well (see gsutil rsync). Please do not contact us with help installing gsutil (we note only that you do not need to run gcloud init).
2020 Update: All data for all challenges stays unchanged.
2019 Update: All data for all challenges stays unchanged.
2018 Update: Detection and keypoint data is unchanged. New in 2018, complete stuff and panoptic annotations for all 2017 images are available. Note: if you downloaded the stuff annotations prior to 06/17/2018, please re-download.
2017 Update: The main change in 2017 is that instead of an 83K/41K train/val split, based on community feedback the split is now 118K/5K for train/val. The same exact images are used, and no new annotations for detection/keypoints are provided. However, new in 2017 are stuff annotations on 40K train images (subset of the full 118K train images from 2017) and 5K val images. Also, for testing, in 2017 the test set only has two splits (dev / challenge), instead of the four splits (dev / standard / reserve / challenge) used in previous years. Finally, new in 2017 we are releasing 120K unlabeled images from COCO that follow the same class distribution as the labeled images; this may be useful for semi-supervised learning on COCO.
2. COCO API
The COCO API assists in loading, parsing, and visualizing annotations in COCO. The API supports multiple annotation formats (please see the data format page). For additional details see: CocoApi.m, coco.py, and CocoApi.lua for Matlab, Python, and Lua code, respectively, and also the Python API demo.
3. MASK API
COCO provides segmentation masks for every object instance. This creates two challenges: storing masks compactly and performing mask computations efficiently. We solve both challenges using a custom Run Length Encoding (RLE) scheme. The size of the RLE representation is proportional to the number of boundaries pixels of a mask and operations such as area, union, or intersection can be computed efficiently directly on the RLE. Specifically, assuming fairly simple shapes, the RLE representation is O(√n) where n is number of pixels in the object, and common computations are likewise O(√n). Naively computing the same operations on the decoded masks (stored as an array) would be O(n).
The MASK API provides an interface for manipulating masks stored in RLE format. The API is defined below, for additional details see: MaskApi.m, mask.py, or MaskApi.lua. Finally, we note that a majority of ground truth masks are stored as polygons (which are quite compact), these polygons are converted to RLE when needed.
4. FiftyOne
FiftyOne is an open-source tool facilitating visualization and access to COCO data resources and serves as an evaluation tool for model analysis on COCO.
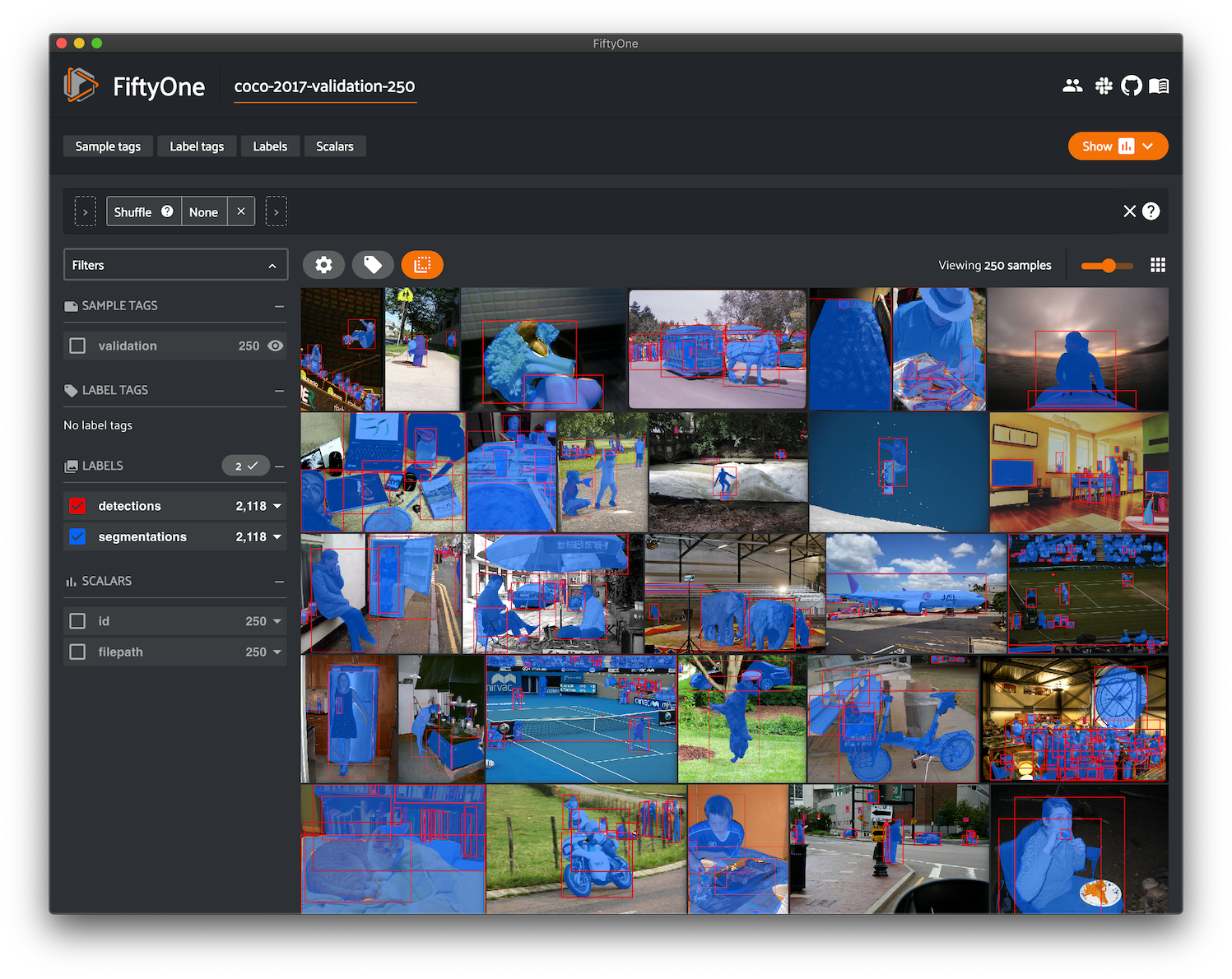
COCO can now be downloaded from the FiftyOne Dataset Zoo:
dataset = fiftyone.zoo.load_zoo_dataset("coco-2017")
FiftyOne also provides methods allowing you to download and visualize specific subsets of the dataset with only the labels and classes that you care about in a couple of lines of code.
dataset = fiftyone.zoo.load_zoo_dataset(
"coco-2017",
split="validation",
label_types=["detections", "segmentations"],
classes=["person", "car"],
max_samples=50,
)
# Visualize the dataset in the FiftyOne App
session = fiftyone.launch_app(dataset)
Once you start training models on COCO, you can use FiftyOne's COCO-style evaluation to understand your model performance with detailed analysis, visualize individual false positives, plot PR curves, and interact with confusion matrices.
For additional details see the FiftyOne and COCO integration documentation.
COCO 2020 Object Detection Task

1. Overview
The COCO Object Detection Task is designed to push the state of the art in object detection forward. COCO features two object detection tasks: using either bounding box output or object segmentation output (the latter is also known as instance segmentation). For full details of this task please see the detection evaluation page. Note: only the detection task with object segmentation output will be featured at the COCO 2020 challenge (more details follow below).
This task is part of the Joint COCO and LVIS Recognition Challenge Workshop at ECCV 2020. For further details about the joint workshop please visit the workshop page. Researchers are encouraged to participate in both the COCO and LVIS Object Detection Tasks (the tasks share identical data formats and evaluation metrics). Please also see the related COCO keypoint, stuff, and panoptic tasks. Whereas the detection task addresses thing classes (person, car, elephant), the stuff task focuses on stuff classes (grass, wall, sky) and the newly introduced panoptic task addresses both simultaneously.
The COCO train, validation, and test sets, containing more than 200,000 images and 80 object categories, are available on the download page. All object instances are annotated with a detailed segmentation mask. Annotations on the training and validation sets (with over 500,000 object instances segmented) are publicly available.
This is the fifth iteration of the detection task and it exactly follows the COCO 2019 Object Detection Task. In particular, the same data, metrics, and guidelines are being used for this year's task. As in 2019 only the instance segmentation task will be featured at the challenge, with winners being invited to present at the workshop. For detection with bounding boxes outputs, researchers may continue to submit to test-dev and val on the evaluation server, but not to test-challenge, and results will not be presented at the workshop. As detection has steadily advanced, the purpose of this change is to encourage the community to focus on the more challenging and visually informative instance segmentation task.
2. Dates
3. New Rules and Awards
- Participants must submit a technical report that includes a detailed ablation study of their submission via CMT. For the technical report, use the following ECCV-based template. Suggested length of the report is 2-7 pages. The reports will be made public. This report will substitute the short text description that we requested previously. Only submissions with the report will be considered for any award and will be put in the COCO leaderboard.
- This year for each challenge track we will have two different awards: best result award and most innovative award. The most innovative award will be based on the method description in the submitted technical reports and decided by the COCO award committee. The commitee will invite teams to present at the workshop based on the innovations of the submissions rather than the best scores.
- This year we introduce single best paper award for the most innovative and successful solution across all challenges. The winner will be determined by the workshop organization committee.
4. Organizers
5. Award Committee
6. Task Guidelines
Participants are recommended but not restricted to train their algorithms on COCO 2017 train and val sets. The download page has links to all COCO 2017 data. The COCO test set is divided into two splits: test-dev and test-challenge. Test-dev is as the default test set for testing under general circumstances and is used to maintain a public leaderboard. Test-challenge is used for the workshop competition; results will be revealed at the workshop. When participating in this task, please specify any and all external data used for training in the "method description" when uploading results to the evaluation server. A more thorough explanation of all these details is available on the guidelines page, please be sure to review it carefully prior to participating. Results in the correct format must be uploaded to the evaluation server. The evaluation page lists detailed information regarding how results will be evaluated.
7. Tools and Instructions
We provide extensive API support for the COCO images, annotations, and evaluation code. To download the COCO API, please visit our GitHub repository. For an overview of how to use the API, please visit the download page. Due to the large size of COCO and the complexity of this task, the process of participating may not seem simple. To help, we provide explanations and instructions for each step of the process on the download, data format, results format, guidelines, upload, and evaluation pages. For additional questions, please contact info@cocodataset.org.